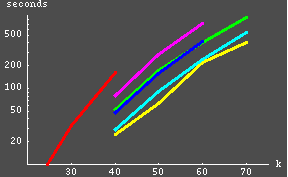
Results
LinPack
 = 46341 matrix size
= 46341 matrix size
using 80% of the clusters memory (leaving enough for X functions) the matrix size is 41449.
| Summer 2004 Beowulf Benchmarking Project |
Results |
LinPack |
| The maximum matrix size as limited by memory capacity:
= 46341 matrix size
using 80% of the clusters memory (leaving enough for X functions) the matrix size is 41449. |
| GOTO -- 16 Processor Network Test | ||
| Network | GFlops | Peak % |
| One Network | 25.42 | 56.7 |
| Both Network | 29.09 | 64.9 |
| For the final (whole network) test with matrix size 41449, a different machine file was used, which declared all of the processors using an independent IP address, instead of linking two processors to each IP. This was done based on an earlier test that indicated that the resulting GFLOP speed was greater if each processor used it's own memory and was addressed by its own Ethernet connection. |
| Using sixteen 1.4 Ghz processors, Rpeak
can be calculated as:
2 flops × 1.4 × 109 Hz × 16 processors = 44.8 GFlops The clusters maximum Benchmark result was 29.09 GFlops, providing us with approximately 64.9% efficiency. |
STREAM |
| This measures memory bandwidth for one processor. |
| Array size = 64 × 106 | ||||
| Memory required = 1464.8 MB | ||||
| Function | Rate (MB/s) | RMS time | Min time | Max Time |
| Copy | 1493.9593 | 0.7164 | 0.6854 | 0.7868 |
| Scale | 1410.6373 | 0.7675 | 0.7259 | 0.8387 |
| Add | 1476.3721 | 1.0785 | 1.0404 | 1.1851 |
| Triad | 1446.4082 | 1.1640 | 1.0619 | 1.3404 |
NetPerf 2.2 |
| This measures the communication bandwidth of the entire network. |
| MB/s transfer rate | Receive | ||
| First | Second | ||
| Send | First | 938.25 | 94.11 |
| Second | 934.33 | 94.15 | |
Procedure |
| The following benchmarks were administered on an 8-node beowulf cluster of the following specifications: |
| Item | Quantity |
| K8D motherboard MSI | 8 |
| 240 AMD CPU Opteron | 16 |
| 512 MB ATP ECC PC2700 | 32 |
| D-DGS Link - 1008 ethernet gigabit switch | 2 |
| Barracuda Gbyte HD Seagate | 4 |
These nodes are diskless, one node acts as a file server for the other seven. The cluster is operated by GinGin64, a 64-bit implementation of Red Hat Linux 8. |
| More information about Cluster Design here. |
High Performance LinPack |
|
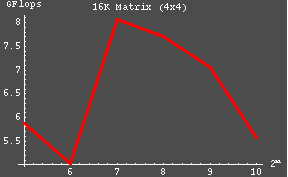
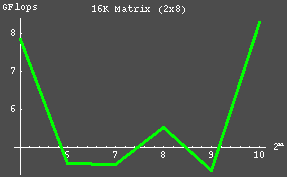
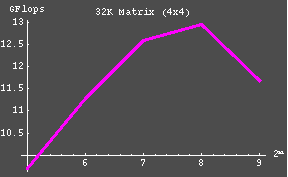
| The majority of the Benchmark testing was done using the ACML 2.0 math libraries. The performance of the other libraries can then be extrapolated on the basis of the ACML results. The matrix sizes 16384 and 32768 consumed 12.5% and 50% of the clusters memory, respectively. The somewhat unsatisfactory results may be due in part to the fact that an insuffienct problem size has yet been used (as a parallel to later recorded findings which indicated that better results are seen when the problem size is sufficiently large as to compose >80% of the available memory. |
| ACML Driver Benchmark Results | |||
| Matrix Size | PxQ | Block Size | GFlops |
| 16384 | 2x8 | 32 | 7.836 |
| 64 | 4.573 | ||
| 128 | 4.565 | ||
| 256 | 5.535 | ||
| 512 | 4.397 | ||
| 1024 | 8.293 | ||
| 4x4 | 32 | 5.883 | |
| 64 | 5.035 | ||
| 128 | 8.067 | ||
| 256 | 7.719 | ||
| 512 | 7.057 | ||
| 1024 | 5.568 | ||
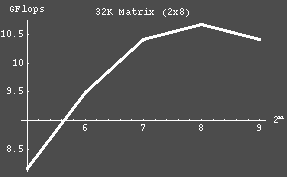
| 32768 | 2x8 | 32 | 8.164 |
| 64 | 9.495 | ||
| 128 | 10.41 | ||
| 256 | 10.68 | ||
| 512 | 10.41 | ||
| 1024 | --- | ||
| 4x4 | 32 | 9.705 | |
| 64 | 11.27 | ||
| 128 | 12.58 | ||
| 256 | 12.95 | ||
| 512 | 11.69 | ||
| 1024 | --- | ||
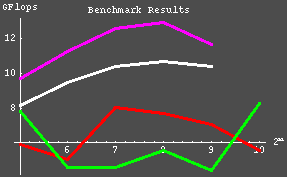
| The following graphs were constructed using the data collected from the previous table. |
 |
 |
 |
 |
 |
|
| The next step is to test the three math libraries that we have available. Using a 15,400 matrix problem size (roughly 95% of one nodes memory capacity) the following data was compiled. |
| Single Processor Results | ||
| Math Library | GFlops | Peak % |
| ACML 2.0 | 2.271 | 81.1 |
| ATLAS 3.5.6 | 2.435 | 87.0 |
| GOTO | 2.489 | 88.9 |
| Next, having seen the superiority of the GOTO libraries, one last set of tests is administered. The cluster has two network switches, one of which is used for NFS and tftpboot, as well as the mpirun executions, and one that does nothing at all. After configuring the second network into the cluster (as an independent connection, not bonded), tests were run on a 4 processor section of the cluster, matrix problem size 20,000 (or roughly 80% of two nodes memory capacity). |
| GOTO -- 4 Processor Network Test | ||
| Network | GFlops | Peak % |
| Primary | 7.785 | 69.5 |
| Secondary | 8.453 | 75.5 |
STREAM |
|
| The STREAM benchmark is a measure of a clusters ability to communicate. The Triad Rate from our benchmark was 1446.4082 MB/s, this gives us the transfer bandwidth between the memory and the processor. |
NetPerf 2.2 |
| The NetPerf test is designed to test the transfer speed of a connection between two computers. This only test the speed on one NIC to another. While executing this benchmark, a problem with the coding of the benchmark occured. It is not possible using NetPerf to route the test through secondary network cards, or secondary network structures, so the results that were obtained from tests sending to the second network are grossly erroneous. However, the primary network results are impressive, yielding 93.82% efficiency. |
Conclusion | |||||||||||||||||||||
| The last thing that I did this summer was to test the running times of the code that Dr. van de Sande and Justin Lambright had written during their summer work. I ran the code and recorded the time that the program output. It was interesting to see that the best results were not obtained in the same way that the optimum benchmark results were reached. In this case, the best results were gotten by using all sixteen processors, but only one network (not both, as was the case with the LinPack). | |||||||||||||||||||||
| |||||||||||||||||||||
|
|
Brett van de Sande,
Jeremy Pace Homepage: http://www.geneva.edu/~bvds and E-mail: bvds@geneva.edu |
|